
What is speaker diarization?
Speaker diarization is a process of separating individual speakers in an audio stream so that, in the automatic speech recognition (ASR) transcript, each speaker's utterances are separated. Each speaker is separated by their unique audio characteristics and their utterances are bucketed together. This type of feature can also be called speaker labels or speaker change detection. Customers who use audio with multiple speakers and want transcripts to appear in a more readable format often use speaker diarization. Example without speaker diarization:
Hello, and thank you for calling premier phone service. Please be aware that this call may be recorded for quality and training purposes. My name is Beth, and I will be assisting you today. How are you doing? Not too bad. How are you today? I'm doing well. Thank you. May I please have your name? My name is Blake.
With speaker diarization:
[Speaker:0] Hello, and thank you for calling premier phone service. Please be aware that this call may be recorded for quality and training purposes.
[Speaker:0] My name is Beth, and I will be assisting you today. How are you doing?
[Speaker:1] Not too bad. How are you today?
[Speaker:0] I'm doing well. Thank you. May I please have your name?
[Speaker:1] My name is Blake.
What is channel diarization?
The outputs from Deepgram's API, with diarized text, can then be used to build downstream workflows. Speaker diarization is different from channel diarization, where each channel in a multi-channel audio stream is separated; i.e., channel 1 is speaker 1 and channel 2 is speaker 2. Channel diarization can be used for one-to-one phone calls, where there is only one speaker per channel. When there are multiple speakers per channel, such as in the recording of a meeting, speaker diarization is needed to separate the speakers.
How does speaker diarization work?
Speaker diarization is generally broken down into four major subtasks:
Detection - Find regions of audio that contain speech as opposed to silence or noise.
Segmentation - Divide and separate those detected regions into smaller audio sections.
Representation - Use a discriminative vector to represent those segments.
Attribution - Add a speaker label to each segment based on its discriminative representation.
Diarization systems can include additional subtasks. For a true end-to-end AI diarization system, one or more of these subtasks may be joined together to improve efficiency. Let's dig a bit deeper into what these subtasks accomplish for speaker diarization.
Detection is often accomplished by a Voice Activity Detection (VAD) model, which determines if a region of audio contains voice activity (which includes but is not limited to speech) or not. For a more precise outcome, Deepgram leverages the millisecond-level word timings that come with our ASR transcripts. This gives us very accurate regions in time where we are confident that there is speech.
Segmentation is often done uniformly, using a very small window of a few hundred milliseconds or a slightly longer sliding window. Small windows are used to ensure that segments contain a single speaker, but smaller segments produce less informative representations; i.e., it is also hard for people to decide who's talking from a very short clip. So, instead of relying on fixed windowing, we use a neural model to produce segments based on speaker changes.
Representation of a segment usually means embedding it. Statistical representations like i-vectors have been broadly surpassed by embeddings like d- or x-vectors that are produced by a neural model trained to distinguish between different speakers.
Attribution is approached in many different ways and is an active area of research in the field. Notable approaches include the Spectral and Agglomerative Hierarchical Clustering algorithms, Variational Bayes inference algorithms, and various trained neural architectures. Our approach successively refines an initial, density-based clustering result to produce accurate and reliable attributions.
Why is speaker diarization important?
Speaker diarization is used to increase transcript readability and better understand what a conversation is about. Speaker diarization can help extract important points or action items from the conversation and identify who said what. It also helps to identify how many speakers were on the audio. Some examples uses are when reviewing a post-call sales meeting and you need to know did if the customer agreed to the business terms or if the salesperson just say they did. Who gave the final buying decision? For real-time educational use, caption diarization would help online students better understand who said what in the classroom. Was it the professor or a student?
What are common use cases for speaker diarization?
As we mentioned above, creating readable transcripts is one major use, but other use cases for diarization include:
Audio/Video/Podcast management - Speaker separated transcripts or captions allow easier searches for company/product attribution and better understanding of viewers or listeners.
Compliance - Determining that a customer agreed to certain business terms in a multi-person meeting.
Conversational AI - A food ordering voicebot trying to determine who is placing the food order when there are multiple adults and children talking.
Education - Transcribing a student question and answer session to parse out the answers given by the professor or the students.
Health - Separate patient and doctor comments for both in-person appointments and phone consultations.
Law enforcement - Parsing who said what in body cam footage or other recordings.
Recruiting - Tracking recruiter and candidate conversations for compliance, bias issues, and review.
Sales Enablement - Tracking who said what in a sales meeting and coaching the salesperson on what to say and when to keep quiet.
Speaker Analysis - Track current and previous comments from a certain speaker during meetings or track talk time during a phone call.
What are the metrics for speaker diarization?
The main metric used for speaker diarization in the business world is the accuracy of identifying the individual speakers or "who spoke what". Most of the measures in academia are measures of "who spoke when". We believe the best way to measure speaker diarization improvement is to measure time base confusion error rate (tCER) and time based time based diarization error rate (tDER).
Time-based Confusion Error Rate (tCER) = confusion time / total reference and model speech time
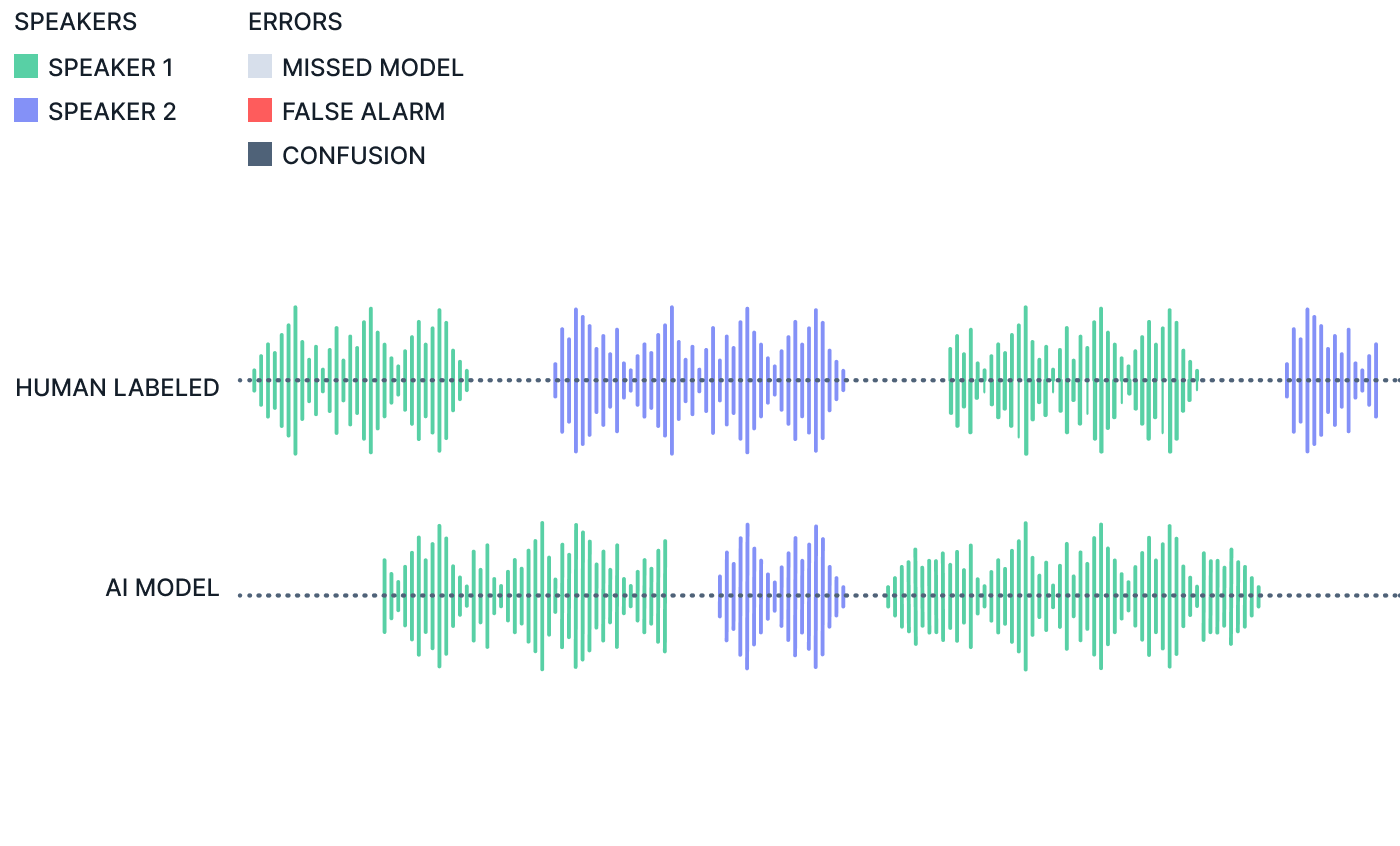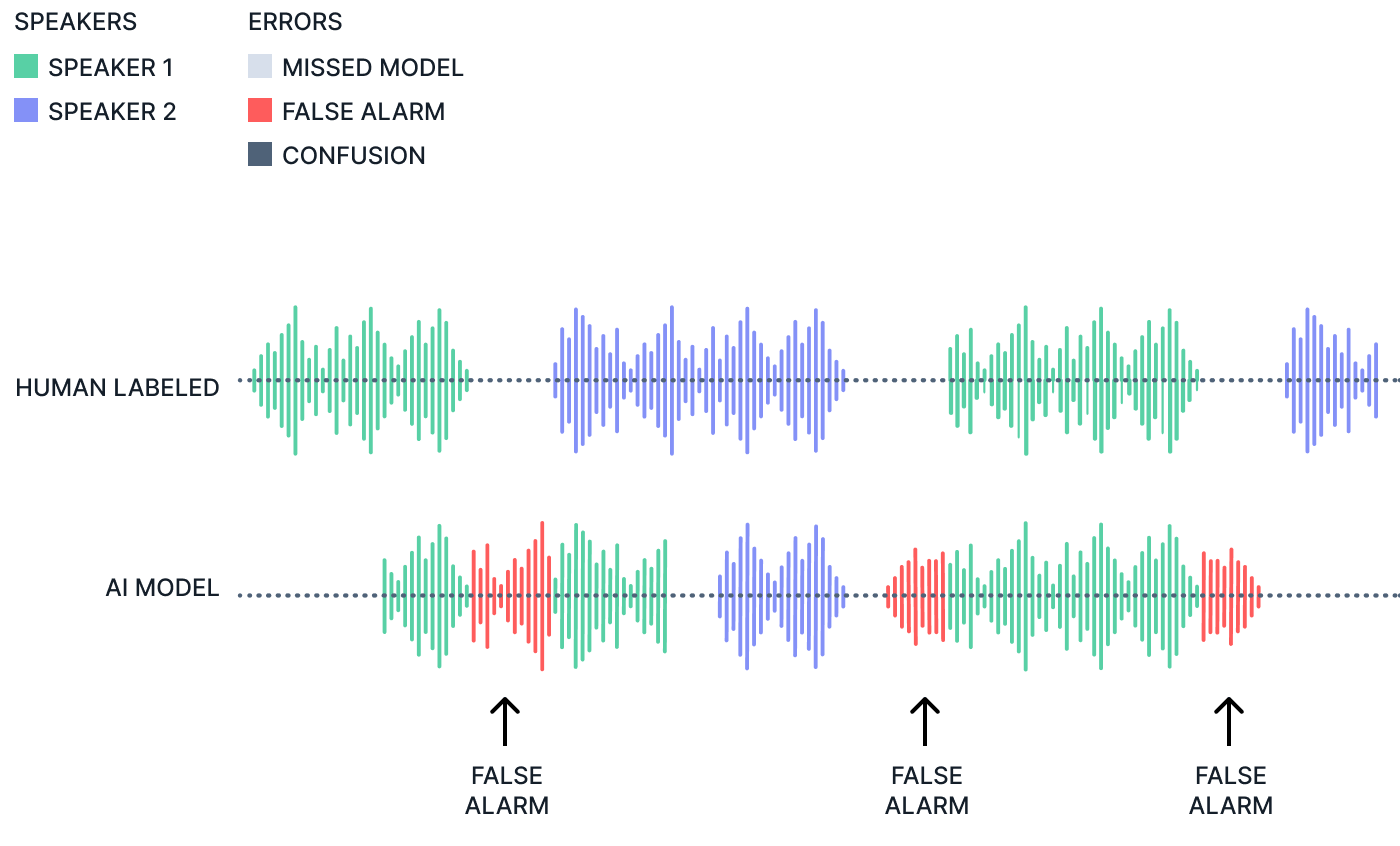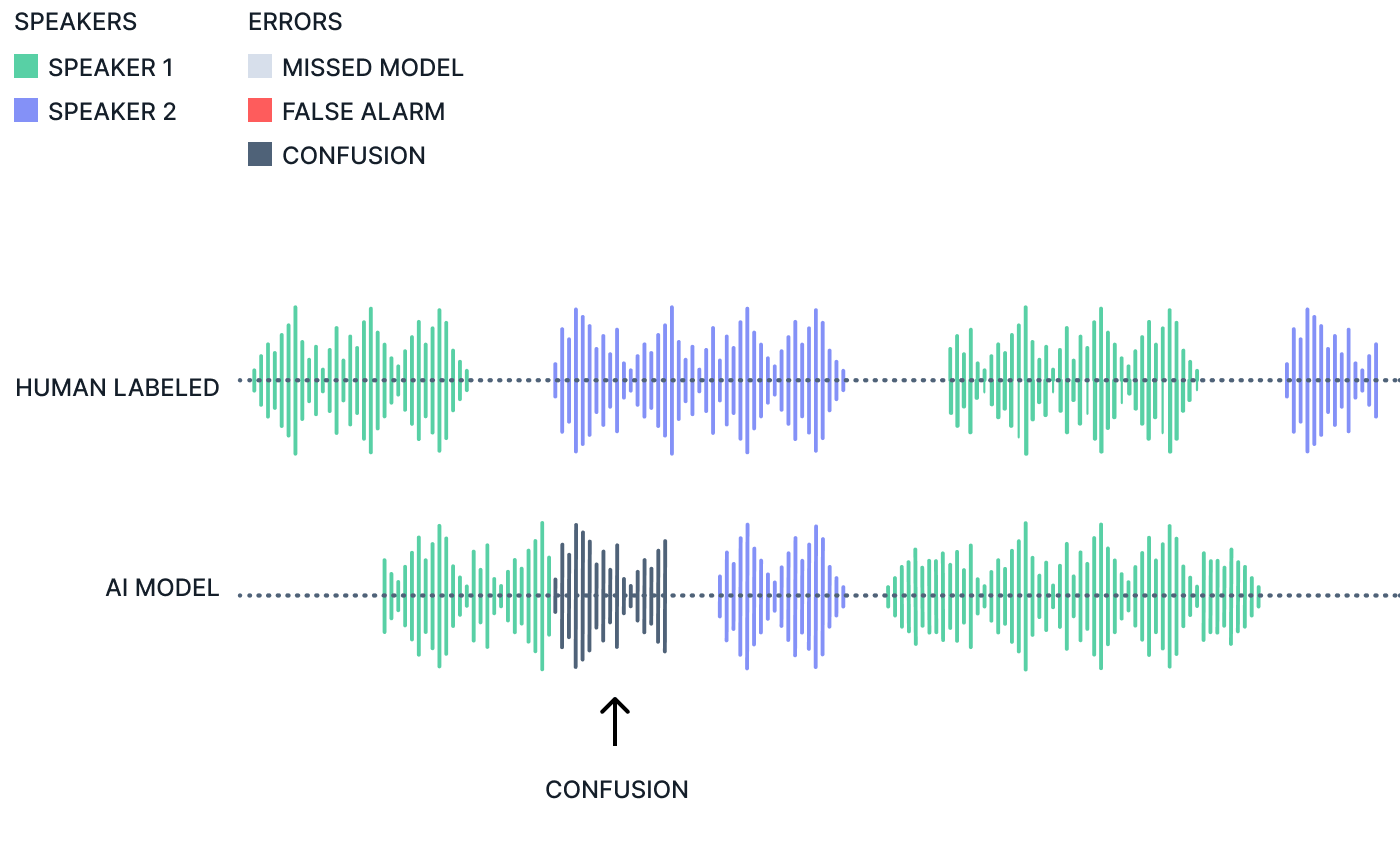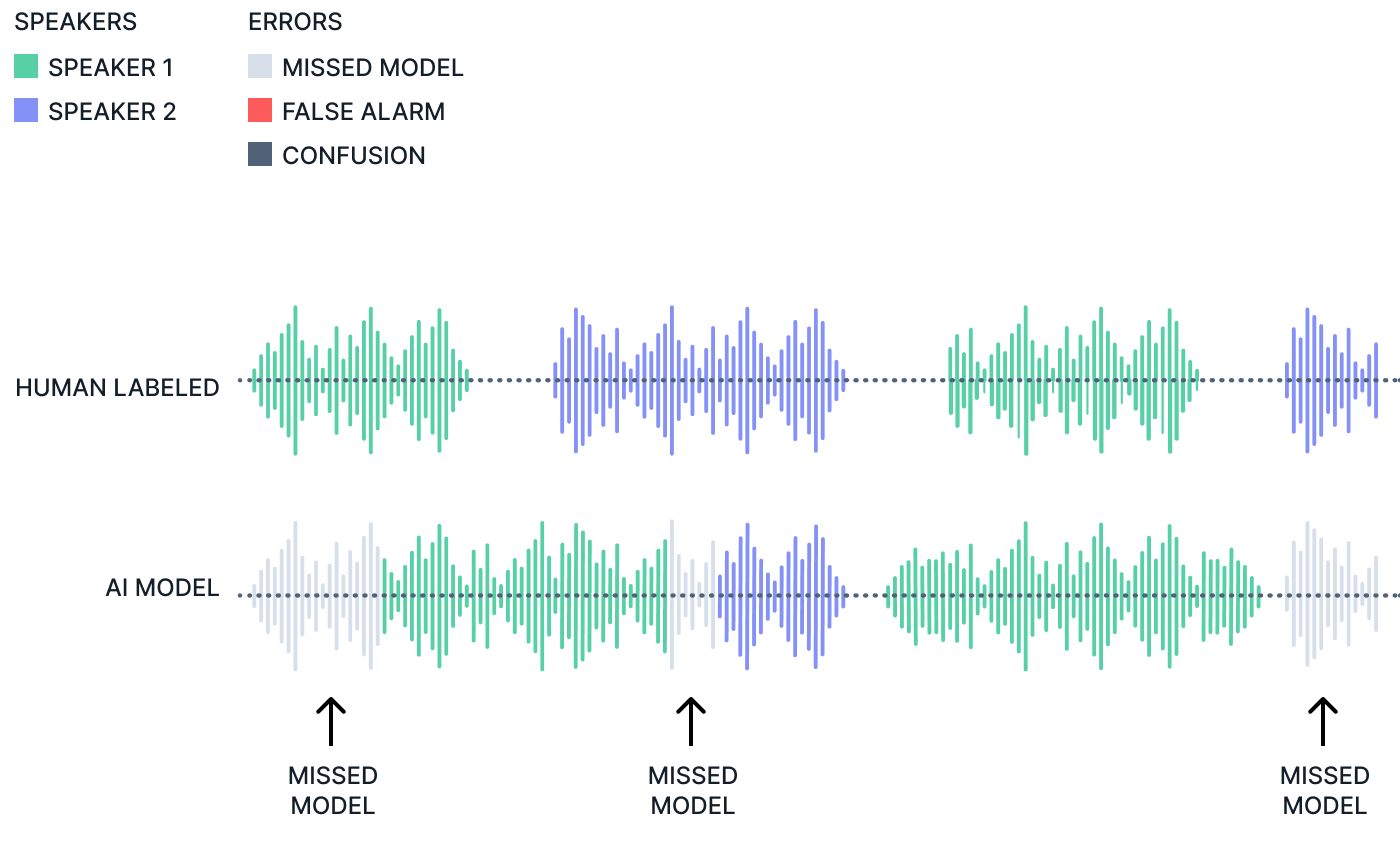
Time-based Diarization Error Rate (tDER) = false alarm time + missed detection time + confusion time / total reference and model speech time
Key M = Missed model, F = False alarm, C = Confusion
tCER is based on how much time the diarization identifies the wrong speaker over the total time of audio with speech. The smaller the CER the better the diarization. If there are four speakers and the diarization process has a CER of 10% then for one hour of spoken audio, it misidentified speakers for 6 minutes. A tCER of less than 10% would be considered very good. However, this measurement is not weighted by the number of speakers or other measures, so you can have a 10% tCER result with identifying one speaker on a two-speaker call when one speaker dominates the conversation for 90% of the time and the secondary speaker only speaks 10%. Deepgram's testing consists of audio with widely varying durations and speaker counts.
The other metric is tDER which adds to tCER by including false alarm time (time the model thinks someone is talking when there is just noise or silence) and missed detection time (time where there is speech but the model does not pick it up as speech). tDER is a more standard measure and can provide some more insights into model performance.
Comparing Deepgram's speaker diarization
Now that we understand how diarization works and how accuracy and errors are assessed, it's important to understand that there are varying capabilities to the diarization features that different ASR providers offer. Deepgram has the following benefits:
No need to specify the number of speakers in the audio. Some ASR providers require you to input the number of speakers in the audio before processing. Deepgram separates the different speakers without any human intervention.
No cap on the number of speakers in the audio. We have seen very high accuracy of speaker identification on audio with 16+ speakers. Other ASR providers may only be able to perform speaker diarization on 4 or less speakers on one channel.
Supports any language Deepgram transcribes. Our speaker diarization is language agnostic. Many providers only offer speaker diarization on English or a handful of other languages, which limits your growth.
Supports both pre-recorded or real-time streaming audio in the cloud or on-prem. While other ASR providers can only perform speaker diarization on pre-recorded audio, Deepgram can do both real-time and pre-recorded audio due to our parallel processing and fast AI model architecture.
The full documentation and implementation guides are available so you can immediately try out our diarization features on our Console.
Deepgram's approach: more voices, without compromise
At a high level, our approach to diarization is similar to other cascade-style systems, consisting of three primary modules for segmentation, embeddings, and clustering. We differ, however, in our ability to leverage our core ASR functionality and data-centric training to increase the performance of these functions, leading to better precision, reliability, and consistency overall.
Speaker diarization is ultimately a clustering problem that requires having enough unique voices in distribution in order for the embedder model to accurately discriminate between them. If voices are too similar, the embedder may not differentiate between them resulting in a common failure mode where two distinct speakers are recognized as one. Out-of-distribution data errors can occur when the training set was not sufficiently representative of the voice characteristics (e.g., strong accents, dialects, different ages in speakers, etc.) encountered during inference. In this failure mode, the embedder may not produce the right number of clusters and the same speaker may be incorrectly given multiple label assignments.
Our diarization accurately identifies speakers in complex audio streams, reducing such errors and resulting in more accurate transcripts through a number of intentional design choices in our segmentation, embedding, and clustering functions and our groundbreaking approach to training.
To overcome even the rarest of failure modes, our embedding models are trained on over 80 languages and 100,000 speakers recorded across a substantial volume of real-world conversational data. This extensive and diverse training results in diarization that is agnostic to the language of the speaker as well as robustness across domains, meaning consistently high accuracy across different use cases (i.e., meetings, podcasts, phone calls, etc.). That means that our diarization can stand up to the variety of everyday life — noisy acoustic environments, ranges in vocal tenors, nuances in accents — you name it.
Our large-scale multilingual training approach is also instrumental to achieving unprecedented speed, since it allows us to employ fast and lean networks that are dramatically less expensive compared to current state-of-the-art approaches, while still obtaining world-class accuracy. We coupled this with extensive algorithmic optimizations to achieve maximal speed within each step of the diarization pipeline. As with Deepgram’s ASR models writ large, the value of our diarization is speed and accuracy. There is no limit to the number of speakers that can be recognized (unlike most alternatives), and the system even performs well in a zero-shot mode on languages wholly unseen during training.

Figure 1: Deepgram Diarization System Architecture
Figure 1: Deepgram Diarization System Architecture
Learn more about Deepgram
Sign up for a Deepgram account and get $200 in Free Credit (up to 45,000 minutes), absolutely free. No credit card needed!
We encourage you to explore Deepgram by checking out the following resources:



